在云的环境,key-value的存储方式有很多优势。这里就不谈是什么优势了,主要看看在SAE 用 kvdb 保存数据,用什么方式好。
json和pickle哪个快?
查了一下json和pickle比较的文章,发现 Pickle vs JSON — Which is Faster? http://kovshenin.com/2010/pickle-vs-json-which-is-faster/ ,得出结论是:
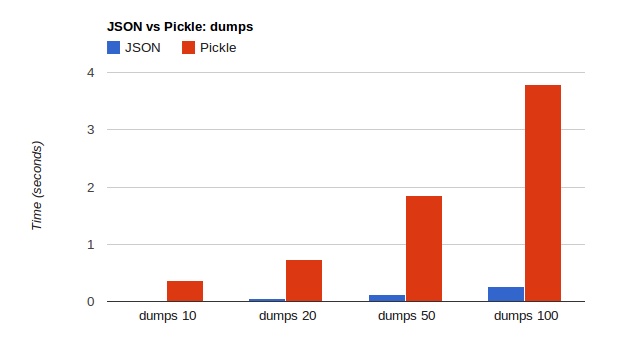
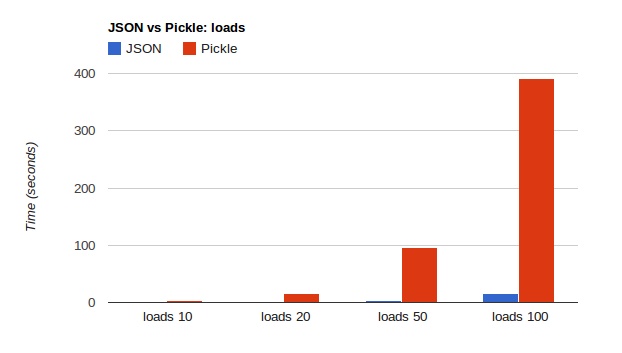
1JSON is 25 times faster in reading (loads) and 15 times faster in writing (dumps)
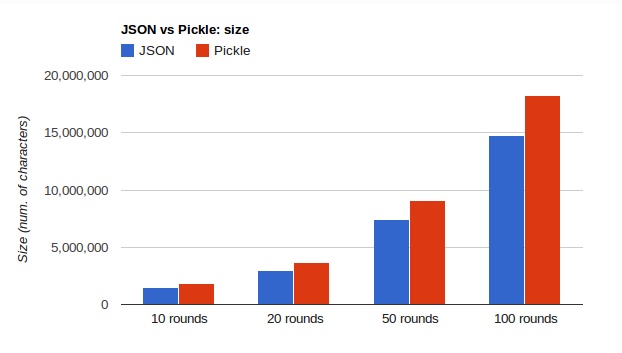
kovshenin 分别在 dumps、loads、size 方面对 json 和 pickle 作了比较,结果如下:
图片:pickle-vs-json-dumps.png
图片:pickle-vs-json-loads.png
图片:pickle-vs-json-size.png
还有没有更快的?
两年前在GAE论坛有人就讨论过这个问题:Finding the absolute fastest way to serialise/deserialise a dictionary on GAE https://groups.google.com/forum/?fromgroups=#!topic/google-appengine-python/TW3eYQrd2O8 (墙外)
Google 工程师 Nick Johnson 给出的建议:
当数据只是简单的字符时可用下面的方法以字符串保存dict数据
1",".join("%s:%d" % x for x in my_dict.iteritems())
还原dict的方法
1dict(x.split(":") for x in my_string.split(","))
这前提是数据里没有“,”和“:”字符,后来Greg 说他采用两个在正常字符串中很难用到的ASCII字符:\x1e 和 \x1f
在SAE kvdb上如何应用?
当你的数据可以用dict保存,则在SAE kvdb里就可以用字符串保存,下面是个人的测试代码,主要看看在kvdb里占用的空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
#! /usr/bin/env python
#coding=utf-8
import tornado.wsgi
import sae
import json
import sae.kvdb
kv = sae.kvdb.KVClient()
settings = {
"debug" : True,
}
def encode_dict(my_dict):
return "\x1e".join("%s\x1f%s" % x for x in my_dict.iteritems())
def decode_dict(my_string):
return dict(x.split("\x1f") for x in my_string.split("\x1e"))
class MainHandler(tornado.web.RequestHandler):
def get(self):
html = """
Hello, world! - Tornado
<form action="" method="post">
<div><textarea cols="40" name="text"></textarea></div>
<div><input type="submit" /></div>
</form>
"""
self.write(html)
def post(self):
my_dict = {'a':'1111','b':'2211a'}
#my_dict = {'a':'1111','b':'2211a','3':'cccc'}
#my_dict = {'a':'1111','b':'2211a','3':'四个中文'}
#my_dict = {'a':'1111','b':'2211a','3':u'四个中文'} #or '四个中文'.encode('utf-8')
my_dict['3'] = self.get_argument('text','')
#my_dict['3'] = self.get_argument('text','').encode('utf-8')
self.write( 'my_dict = %s <br/>' % json.dumps(my_dict) )
my_string = encode_dict(my_dict)
for i in xrange(1000):
kv.set('k_%d'%i, my_string)
self.write('encode_dict >> total_size: %d <br/>' % kv.get_info()['total_size'])
my_string = json.dumps(my_dict)
for i in xrange(1000):
kv.set('k_%d'%i, my_string)
self.write('json.dumps >> total_size: %d <br/>' % kv.get_info()['total_size'])
my_string = my_dict #pickle
for i in xrange(1000):
kv.set('k_%d'%i, my_string)
self.write('pickle.dumps >> total_size: %d <br/>' % kv.get_info()['total_size'])
app = tornado.wsgi.WSGIApplication([
(r"/", MainHandler),
])
application = sae.create_wsgi_app(app)
在文本框里分别输入四个字母、四个中文的结果是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 使用 self.get_argument('text','')
my_dict = {"a": "1111", "3": "cccc", "b": "2211a"}
encode_dict >> total_size: 29000
json.dumps >> total_size: 42000
pickle.dumps >> total_size: 58000
#---
my_dict = {"a": "1111", "3": "\u56db\u4e2a\u4e2d\u6587", "b": "2211a"}
encode_dict >> total_size: 49000
json.dumps >> total_size: 62000
pickle.dumps >> total_size: 78000
# 使用 self.get_argument('text','').encode('utf-8')
my_dict = {"a": "1111", "3": "cccc", "b": "2211a"}
encode_dict >> total_size: 23000
json.dumps >> total_size: 42000
pickle.dumps >> total_size: 60000
#---
my_dict = {"a": "1111", "3": "\u56db\u4e2a\u4e2d\u6587", "b": "2211a"}
encode_dict >> total_size: 31000
json.dumps >> total_size: 62000
pickle.dumps >> total_size: 104000
结论
当你的数据比较简单,如:
1news_dict = {'id':'1', 'author':'yourNmae', 'content':'主体内容,这里有很多了'}
不需要一些数据运算、筛选,如搜索某些字段、排序等,当数据量很大时还想保持高性能,就用kvdb存储,并把dict转为字符串保存。
本文网址: https://pylist.com/topic/24.html 转摘请注明来源