list 去重是编程中经常用到的,python 的去重方式很灵活,下面介绍多种去重方式,并比较得出最高效的方式。
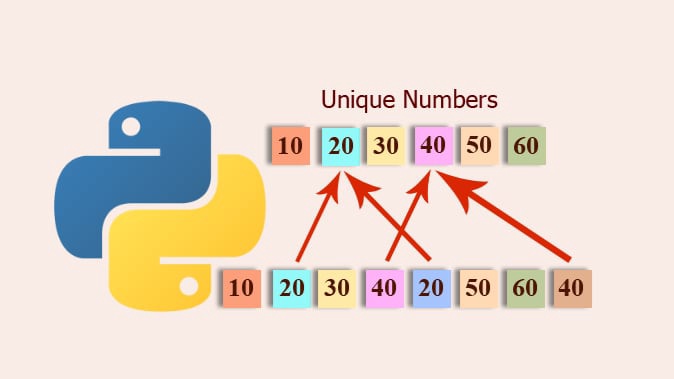
直接贴出最后结果
1
2
3
list(set(seq))
# or
{}.fromkeys(seq).keys()
完整的比较测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
from random import shuffle, randint
import re
from sets import Set
def f1(seq): # Raymond Hettinger
# not order preserving
set = {}
map(set.__setitem__, seq, [])
return set.keys()
def f2(seq): # *********
# order preserving
checked = []
for e in seq:
if e not in checked:
checked.append(e)
return checked
def f3(seq):
# Not order preserving
keys = {}
for e in seq:
keys[e] = 1
return keys.keys()
def f4(seq): # ********** order preserving
noDupes = []
[noDupes.append(i) for i in seq if not noDupes.count(i)]
return noDupes
def f5(seq, idfun=None): # Alex Martelli ******* order preserving
if idfun is None:
def idfun(x): return x
seen = {}
result = []
for item in seq:
marker = idfun(item)
# in old Python versions:
# if seen.has_key(marker)
# but in new ones:
if marker in seen: continue
seen[marker] = 1
result.append(item)
return result
def f5b(seq, idfun=None): # Alex Martelli ******* order preserving
if idfun is None:
def idfun(x): return x
seen = {}
result = []
for item in seq:
marker = idfun(item)
# in old Python versions:
# if seen.has_key(marker)
# but in new ones:
if marker not in seen:
seen[marker] = 1
result.append(item)
return result
def f6(seq):
# Not order preserving
return list(Set(seq))
def f7(seq):
# Not order preserving
return list(set(seq))
def f8(seq): # Dave Kirby
# Order preserving
seen = set()
return [x for x in seq if x not in seen and not seen.add(x)]
def f9(seq):
# Not order preserving
return {}.fromkeys(seq).keys()
def f10(seq, idfun=None): # Andrew Dalke
# Order preserving
return list(_f10(seq, idfun))
def _f10(seq, idfun=None):
seen = set()
if idfun is None:
for x in seq:
if x in seen:
continue
seen.add(x)
yield x
else:
for x in seq:
x = idfun(x)
if x in seen:
continue
seen.add(x)
yield x
def f11(seq): # f10 but simpler
# Order preserving
return list(_f10(seq))
def _f11(seq):
seen = set()
for x in seq:
if x in seen:
continue
seen.add(x)
yield x
import time
def timing(f, n, a):
print f.__name__,
r = range(n)
t1 = time.clock()
for i in r:
f(a); f(a); f(a); f(a); f(a); f(a); f(a); f(a); f(a); f(a)
t2 = time.clock()
print round(t2-t1, 3)
def getRandomString(length=10, loweronly=1, numbersonly=0,
lettersonly=0):
""" return a very random string """
_letters = 'abcdefghijklmnopqrstuvwxyz'
if numbersonly:
l = list('0123456789')
elif lettersonly:
l = list(_letters + _letters.upper())
else:
lowercase = _letters+'0123456789'*2
l = list(lowercase + lowercase.upper())
shuffle(l)
s = ''.join(l)
if len(s) < length:
s = s + getRandomString(loweronly=1)
s = s[:length]
if loweronly:
return s.lower()
else:
return s
testdata = {}
for i in range(35):
k = getRandomString(5, lettersonly=1)
v = getRandomString(100 )
testdata[k] = v
testdata = [int(x) for x in list('21354612')]
testdata += list('abcceeaa5efm')
class X:
def __init__(self, n):
self.foo = n
def __repr__(self):
return "<foo %r>"%self.foo
def __cmp__(self, e):
return cmp(self.foo, e.foo)
testdata = []
for i in range(10000):
testdata.append(getRandomString(3, loweronly=True))
#testdata = ['f','g','c','d','b','a','a']
order_preserving = f2, f4, f5, f5b, f8, f10, f11
order_preserving = f5, f5b, f8, f10, f11
not_order_preserving = f1, f3, f6, f7, f9
testfuncs = order_preserving + not_order_preserving
for f in testfuncs:
if f in order_preserving:
print "*",
timing(f, 100, testdata)
在我机器上运行结果
1
2
3
4
5
6
7
8
9
10
* f5 3.51
* f5b 3.49
* f8 2.02
* f10 2.57
* f11 2.54
f1 1.54
f3 1.25
f6 1.36
f7 0.89
f9 0.89
总结
下面两种最高效
1
2
3
4
5
6
7
def f7(seq):
# Not order preserving
return list(set(seq))
def f9(seq):
# Not order preserving
return {}.fromkeys(seq).keys()
去除文件\r\n
1
2
3
with open("file.txt") as rf, open("out.txt", "w") as wf:
for line in rf:
wf.write("%s\r\n" % line.strip())
本文网址: https://pylist.com/topic/75.html 转摘请注明来源